
In 2024, Digital Promise released AI in Higher Education, a database of more than 300 studies that provides a snapshot of how institutions across the globe are using and studying AI. The project revealed familiar challenges that can come with research studies: paywalls slowed review, manual tagging proved difficult to scale, and inconsistencies in coding accumulated into noise. Automated coding can provide structure, but strict rules can miss important context. The challenge is balancing consistency with nuance, an insight that shaped the development of PRISM.
These challenges led the team at Digital Promise to design a new approach that blends automation with human review.
PRISM (Pipeline for Research Insights and Shared Meaning) is a tool developed by Digital Promise to make research analysis faster and more transparent. It helps teams organize and review studies by automating several of the most time-consuming steps in evidence synthesis, such as importing new research records and extracting study details like metadata and methods.
Researchers decide what information to extract and review the results themselves, keeping people, and not automation, at the center of interpretation. Within the PRISM pipeline, built in Airtable, each record and its extracted content can be viewed side-by-side, allowing reviewers to compare original materials with AI-generated fields. A “Human Reviewed” tag can be added to indicate that a record has been checked for accuracy. The screenshot below offers a visual example of this part of the workflow.
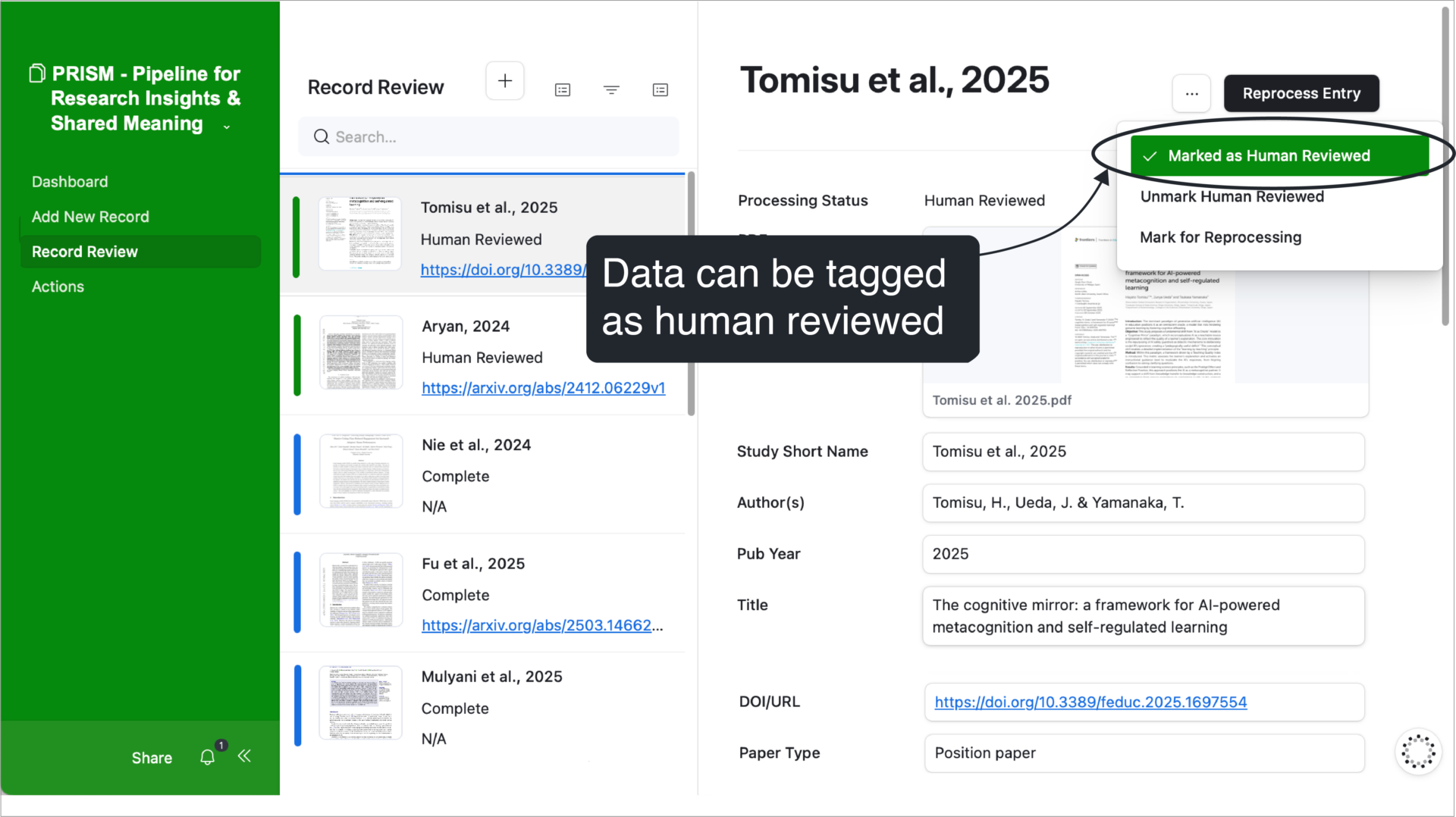
This example above shows how a reviewer can mark a study as having been checked for accuracy.
PRISM connects Airtable, GitHub, and OpenAI’s API to help organize and analyze research studies. When new studies are added, PRISM can automatically pull in their information and use language models to identify key details, like a study’s methods or focus. Researchers can then review and refine what the system extracts, choosing what information to keep or adjust. Everything happens within Airtable, so the process stays organized and easy to follow. Research teams can decide what kinds of data matter most for their work and set up PRISM to capture those details in a consistent way.

The screenshot above highlights how transparent prompt design allows reviewers to inspect how the model reaches its decisions.
By automating routine steps like collecting records and organizing study details, PRISM gives researchers more time to focus on understanding what the evidence means. It helps teams keep their process consistent and reduces the risk of small errors that can occur when everything is done by hand. At the same time, people stay in charge of interpreting the findings—PRISM’s role is to handle the repetitive parts of research so that human judgment can guide the rest.
As research teams continue to look for better ways to connect evidence with daily decision-making, future versions of PRISM could build on what already works. One possible direction would be to bring PRISM into Microsoft Teams, allowing people to use it in the same space where they already meet and share ideas. In that setting, users might ask questions in plain language such as, “How does this study describe its participants?” or “Is there a table showing these results?”
PRISM could then respond in the chat, showing where the information appears in the document and linking to the source. Everyone in the conversation could see and build on these exchanges, turning the process of finding and interpreting evidence into something more open and collaborative. While this next step is still a possibility, it points toward how tools like PRISM could make research use more transparent, interactive, and connected to the way teams already work.
PRISM offers a model for how automation and human expertise can work together to strengthen research. By simplifying the technical steps of evidence synthesis while keeping interpretation in human hands, it shows a path toward more open, adaptable, and trustworthy research processes. Whether used to organize a single project or to build large, shared databases, PRISM demonstrates that transparency and efficiency don’t have to be at odds—they can evolve together.
Interested in trying PRISM for yourself? Learn more about PRISM’s design and workflow by visiting the PRISM GitHub repository.
PRISM was developed through a collaboration between Maxwell Cole and Digital Promise, with support from the Gates Foundation. Any opinions or recommendations expressed are those of the authors and do not necessarily reflect the views of the Gates Foundation.